Back
Theater or Reality: Emerging Economic Power in Machine Learning and Artificial Intelligence Startups
Lonne Jaffe | March 29, 2019| 1 min. read

Artificial intelligence systems powered by machine learning have been creating headlines with applications as varied as generating realistic-looking photos of fake celebrities, making restaurant reservations by phone, creating music, sorting cucumbers, and distinguishing chihuahuas from muffins.
Media buzz aside, many fast-growing startups are using machine learning (ML) techniques such as support vector machines, Bayesian networks, and decision trees to learn from data, make predictions and enhance business decision making. Just this past week, in March 2019, three of the pioneers of neural networks, another important machine learning technique, won the Turing Award, generally recognized as the highest distinction in computer science.
At Insight Partners, we’re sometimes asked the question: what makes a startup whose focus is machine learning a good investment? This question is particularly relevant given the current prevalence of “machine learning theater” – companies pretending to use machine learning to make their technology seem more sophisticated or to get a higher valuation.
This post lays out an answer to this question, discussing how ML is transforming some businesses and industries, and discussing who is most likely to benefit from this capability.
Like any source of economic power, ML has the potential to reshape industries and fundamentally change what are considered to be core or non-core functions in various companies, challenging some prevailing “theory of the firm” assumptions.
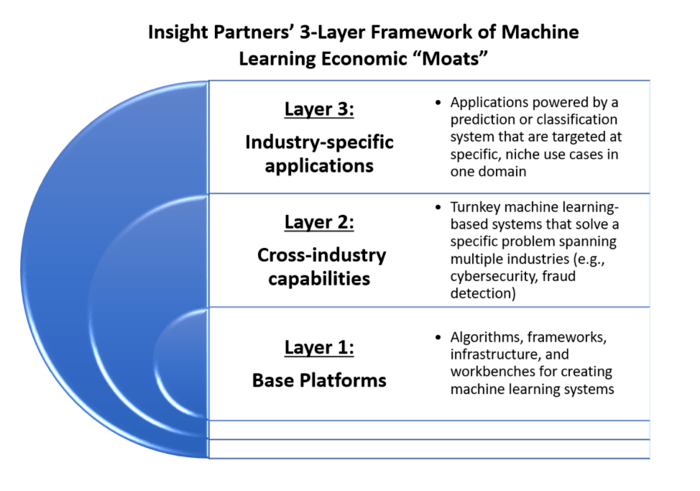
This post describes a simplified three-layer framework for thinking about the kinds of economic power, or “moats” that belong to category defining technology businesses that are using ML to grow at scale:
Layer 1: Base platform companies: these companies deliver algorithms, frameworks, infrastructure, and workbenches for creating machine learning systems.
Layer 2: Cross-industry capability companies: these companies deliver turnkey machine learning-based systems that solve a specific problem spanning multiple industries, such as cybersecurity or fraud detection.
Layer 3: Industry-specific application companies: these companies deliver applications powered by a prediction system that are targeted at specific, often niche, use cases in a particular domain.
While this blog is focused primarily on the topic of which ML companies make good investments, this framework may also be helpful in considering job opportunities at ML startups (“which ML-based company should I work for?”) or for companies thinking through build vs. buy decisions (“should I try to build this ML capability myself, or should I plan to buy it from someone else?”).
Layer 1: Base platforms
This layer is the technology upon which machine learning systems are built, including algorithms, frameworks, runtime engines, toolkits, and workbenches.
- Much of the best technology at Layer 1 is either open source or delivered as-a-service by large public cloud vendors with track records of continuously lowering prices. Startups with a strategy of “we have a product that is not as good as the open source or public cloud alternatives, it’s improving more slowly than they are, and it’s also more expensive” will often struggle. They can gain some adoption if they have enough investor subsidization, but the approach becomes challenging in the longer term if they can’t find a source of differentiation. Many open source offerings such as TensorFlow (originally built by Google) and PyTorch (primarily developed by Facebook AI research) are improving very rapidly, as are public cloud offerings such as AWS Sagemaker. Users care about the pace of improvement, not only current features and functions. Many open source and public cloud offerings are flexible enough to address various different types of ML problems.
- Compute, storage, and Layer 1 offerings continue to drop in price. Using cloud platforms, it’s easy to spin up huge amounts of storage and computing power. This removes a significant resource constraint when it comes to the task of developing ML applications and gives enormous flexibility to anyone working on ML problems who has access to the Internet. Special-purpose hardware advances such as tensor processing units accelerate computationally-intensive tasks that are common in ML applications. Vendors that are used to locking customers into proprietary platforms and then slowly raising prices can scare customers away, sending them to public cloud vendors with a track record of continuously adding new capabilities while lowering prices.
- The ML research community in academia is active, large, and well-funded. Across academia and industry, large groups of researchers are focused on improving the algorithms and tooling at Layer 1. This community benefits from philanthropy and receives significant levels of government funding from countries such as Canada, China, and the US.
- Economic moats are hard to build at Layer 1. Building a sustainably differentiated business at Layer 1 can require an enormous investment in research & development, brand marketing, and sales over long time horizons. Startups have emerged to provide support and proprietary capabilities around popular ML open source frameworks. These startups, however, often have to compete with the public cloud platforms even as they leverage the same open source projects for their own workbench-as-a-service offerings. Public cloud vendors take advantage of their massive scale to regularly lower prices and invest in security features.
- The best businesses at Layer 1 benefit from talent network effects and application ecosystems. As a Layer 1 vendor gets to scale, talent and familiarity in the market naturally build around their product, and technology leaders bring their skills with them from job to job, sometimes advocating for a vendor upon starting in a new role at a new company. Some of the most sustainable businesses at Layer 1 also recruit developers to build turnkey applications on top of their platform, creating a second network effect whereby the platform becomes more appealing to future users and developers.
Layer 2: Cross-industry capabilities
This layer includes cross-industry turnkey machine learning capabilities. These are prediction or classification systems that solve problems for customers that are not “core” to their business or industry, such as cybersecurity and fraud detection.
- Customers of products at Layer 2 may be generous with their data as long as it’s treated carefully. For example, cybersecurity data belonging to a bank or hospital, while sensitive, is often not considered to be a source of strategic differentiation. Banks and hospitals simply want to be using the best cybersecurity system, the one that is improving the most rapidly, and the one that will be the most effective at defending against attacks. As long as companies and governments are confident that their cybersecurity data will be treated securely, many are willing to give this data to a scaling software startup. By doing so, the customers can in return reap the benefits of continuous improvements in the startup’s ML system.
- In some cases, ML systems at Layer 2 can generate “data scale” economic power by virtue of having access to more data for training models and better feedback on the accuracy of machine predictions. With more scale, companies can have access to more training data (the historical corpus of data used to train models) and better feedback data (how accurate was a particular classification or recommendation?). This can give the market leader a powerful data scale advantage, one of the advantages that, for example, Google enjoys in search. For example, an Insight investment, Recorded Future uses ML for cybersecurity threat intelligence. Recorded Future’s technology stack includes models that can predict the likelihood of product vulnerabilities being exploited and can assess the risk that a specific Internet IP address will behave maliciously in the future, even if no such problematic behavior has yet been seen. As Recorded Future continues to scale rapidly, all corporate customers will inherit the improvements in its cybersecurity predictions.
- At Layer 2, economic power is dependent partially on whether there are steady returns to incremental data. The kind of economic moat that comes from differentiated access to data can be weakened if there are rapidly decreasing returns to marginal data. In some domains, once a model is “trained up,” receiving additional data may not move the needle very much. Using ML can still be a good idea even if there are diminishing marginal returns to data, but the system won’t be a source of competitive differentiation. It won’t yield a data scale advantage, and competitors may find it easy to obtain the relatively small amount of data needed to effectively compete. In other domains, models may have an insatiable appetite for more data, continuing to improve indefinitely. This can give data scale power to the leader in a segment – and this data scale power is additive to all of the typical advantages that accrue to a leader in a software segment. This topic is challenging to diligence effectively at an early stage in a startup’s existence, but once a ML system has achieved real world traction it becomes a little easier to observe trends in how much model improvement comes from incremental data.
- ML systems at Layer 2 can benefit from more traditional network effects in addition to data scale effects. For example, in cybersecurity, a ML system deployed by a vendor across multiple customers can learn from multiple customers in parallel. In some cases, it can learn enough from an attack on one customer to inoculate a second customer even before the second customer gets attacked. With this type of system, all customers may gravitate to the system with the most scale, to benefit from “herd immunity.”
- At Layer 2, the build vs. buy decision faced by corporate customers favors buying. For an enterprise to build a Layer 2 ML application, they will have to hire specialized ML talent and obtain the relevant domain expertise. They will have to absorb all of the expenses associated with building and improving the system and they will only have access to their own data. By contrast, if they consume this ML capability from a market leading startup they can inherit all of the data scale and network effect benefits. This can free up any ML talent they have to instead focus on building higher level, industry-specific capabilities that will give them a real competitive advantage.
- Human judgment can be an important complement to a Layer 2 ML system. As discussed in Prediction Machines: The Simple Economics of Artificial Intelligence, some human tasks, such as judgment, are economic complements to ML systems and can increase in value as Layer 2 applications are widely adopted. For example, Insight Partners invested in Featurespace, which uses Bayesian statistics to fight fraud by modeling and predicting behavior. The system can produce a fraud score for every transaction, but it’s most powerful when this machine prediction is paired with high quality human judgement about what to do (e.g., perhaps approve the credit card transaction even though there is some modest fraud risk since it is such a valued customer). Of course, other human tasks are economic substitutes and are thus more likely to be displaced by a ML system. This displacement can be disruptive to many individual careers, businesses, and industries. It can also allow entirely new kinds of business models to emerge which can unlock additional pools of labor.
Layer 3: Turnkey, industry-specific applications
Many industry-specific applications can be improved with prediction or classification systems that learn from data. These ML capabilities have the potential to dramatically increase efficiency. Netflix in entertainment or Amazon in retail demonstrate that even something as simple as a recommendation engine can help to reshape entire industries and value chains.
- ML-powered applications can be very powerful even while being somewhat niche. For example, Insight Partners invested in Tractable, which has ML technology currently focused on estimating the cost of repairing a damaged vehicle based on photos or videos. This technology is used by auto insurance companies and has the potential to benefit body shops, drivers, and even car manufacturers. Another Insight investment, Precision Lender, has a ML-powered system named Andi that makes real-time, contextually relevant recommendations to bankers about how to best price deals, such as loan offers. While Andi performs a relatively narrow task in the overall banking process, it can have significant positive impacts on banking customer satisfaction and bank profitability.
- At Layer 3, customers will sometimes have a bias towards “build” in a build vs. buy analysis. It can be challenging to get customers to part with data that they view as strategic or to cede key functions to a vendor when they view those functions as core to their identity as a firm. At Layer 3 many enterprises may, at least initially, try to “do it themselves” with their own data. Even though it’s hard for them to recruit high-caliber ML talent to build in-house prediction systems, many will try. Because of this obstacle, some Layer 3 machine learning startups are rethinking the traditional boundaries of a software vendor and going direct to the end consumer, competing against incumbents in a vertical industry. This is seen in Fintech where countless startups are disintermediating banks. The incumbents might have otherwise been the startup’s customers, but if a startup can own the end user relationship directly, it can ensure that it has a fresh source of training and feedback data to improve its products; legacy incumbents may get cut out entirely.
- Marginal increases in prediction accuracy can yield significant increases in utility as ML systems pass certain precision thresholds. Going from 98% accuracy to 99.9% accuracy in a system improves the error rate 20x (from 2% to 0.1%). This improvement can be extremely valuable in contexts such as self-driving cars where error tolerance is very low. NYU recently open-sourced a breast cancer screening model trained on over 200,000 mammography exams, that uses deep convolutional neural networks to predict the presence of malignant breast tumors. According to the researchers, “We experimentally show that our model is as accurate as an experienced radiologist and that it can improve the accuracy of radiologists’ diagnoses when used as a second reader.” For some less life-or-death applications, we may soon pass prediction accuracy thresholds beyond which humans can be taken “out of the loop” entirely, which can fundamentally transform business models and industries.
Conclusion
To build a sustainable business at Layers 1, 2, or 3 requires both having investors with very long time horizons and the ability to attract and retain high caliber talent. Many incumbent technology vendors have neither.
This will likely continue to shift economic power from legacy incumbents to growth-stage startups as well as the small number of big, public companies who have curated investors willing to let them invest over many years.