At Insight, we have been closely monitoring the rise of enterprise adoption of artificial intelligence (AI) for years – from the industry-specific applications of AI we first started tracking in 2017, the “MLops” infrastructure companies we discussed in 2021, and, along with the rest of the world, the interesting generative AI use cases that have shown up over the last 12 months.
Recently, from conversations with enterprise executives through our IGNITE program, as well as numerous conversations with founders, we realized that the tools required to implement generative AI use cases, or “LLMops” tools, differ from the toolchain for more traditional prediction system machine learning (ML) models, or “MLops.”
Both MLops (machine learning operations) and LLMops (large language model operations) refer to the combination of tools and infrastructure needed to train, deploy, and maintain a machine learning model.
- MLops is used for systems of prediction: machine learning models that typically perform objective-focused tasks (e.g., Tractable AI’s computer vision models that take pictures of cars and assess the damage done). The outputs in these models are usually recommendations, classifications, or predictions.
- LLMops is used to build systems of creation: generative AI applications that are often open-ended or qualitative and generate new content (e.g., Jasper AI creates marketing copy in the voice of your company).
How and why MLops differs from LLMops
Enterprises need different tools for generative AI vs. traditional prediction system ML models. Some reasons may include:
Transfer learning
Generative AI and predictive AI applications are created differently. Many generative AI products start with a pre-trained foundation model, which is then customized for a specific downstream use case. This is a different, and in some ways easier, process than creating a new, predictive ML model from scratch. Building predictive ML involves gathering data, annotating data, training the model, tuning different hyperparameters and model inputs, etc.
By contrast, enterprises building generative AI select the LLM, fine-tune it with new data, and/or provide context by attaching relevant reference data within the LLM prompts. This process of adapting a pre-trained generative LLM is often easier than creating a new predictive ML model from scratch, and that’s a big part of the reason we’ve seen an outpouring of generative AI products from incumbent software vendors over the last year.
Compute management
A second difference is in the computational resources required. The original pre-training of LLMs often requires orders of magnitude more compute. Even when leveraging a pre-trained LLM, running an LLM — what’s called “inference”— is often very compute intensive, vs. predictive ML models, which can get away with smaller amounts of computational resources for inference.
As a result, runtime infrastructure efficiency management, whether it is implemented by tuning the model architecture, optimizing how the compute scales, or taking another approach, is critical for LLM deployments.
Feedback loops
Many (although not all) predictive ML models will produce clear performance metrics (e.g., the accuracy of a diagnosis outputted by an ML model trained on medical images, such as for our portfolio companies Overjet, Iterative Health, or ScreenPoint Medical).
Generative AI models, on the other hand, typically produce more qualitative output. These open-ended generative tasks are sometimes harder to evaluate. Reinforcement learning from human feedback (RLHF) in a generative AI context is one way to gather human feedback data that can be used to fine-tune models to improve their performance. Gathering and using RLHF-type data requires tools for collecting feedback that are different from the tools used with predictive ML.
Another concept is RLAIF (or reinforcement learning from AI feedback), in which an LLM is fine-tuned using feedback generated by an AI (sometimes an AI trained partially on human feedback). There is also the Constitutional AI approach being used by Anthropic, which involves fine-tuning an LLM using a list of rules or values that are important to humans. For many LLM use cases, incorporating feedback using an ongoing streamlined workflow can improve the reliability of models. Trust, reliability, and safety have become an important emerging economic moat for early generative AI products.
Click to expand the image below.
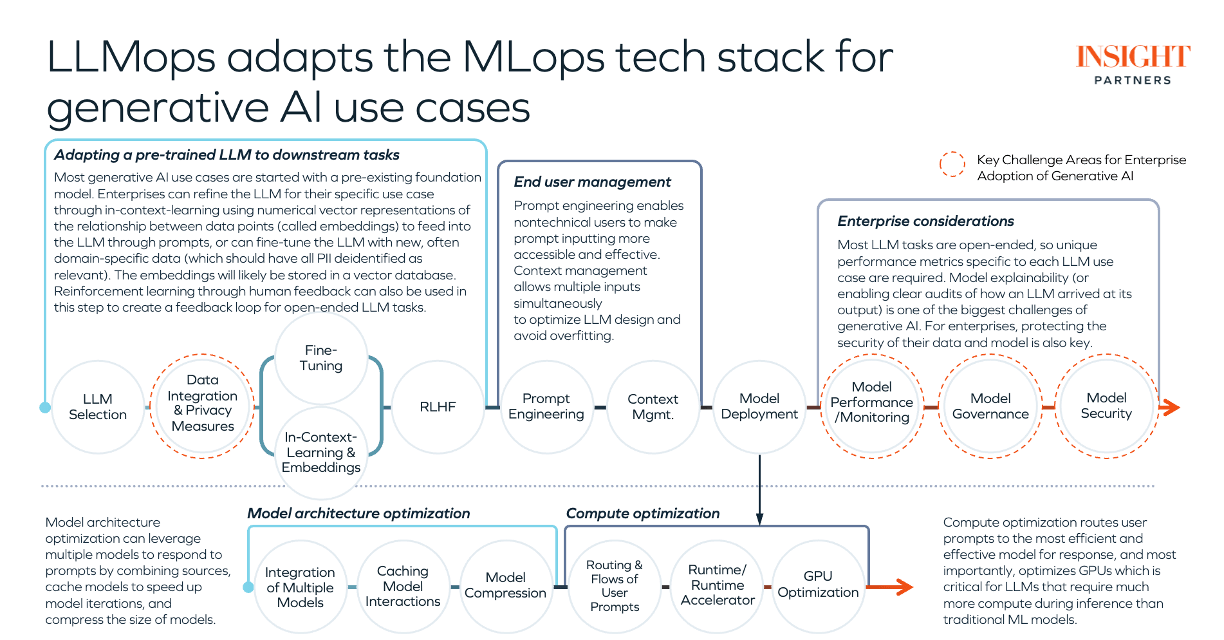
Where LLMops and MLops converge
For enterprise use cases, many critical pieces of the ML pipeline are shared between LLMops and predictive MLOps, including:
- Data privacy: Data and software code used in prompts or in fine-tuning LLMs must be treated with care to avoid accidentally revealing personal information. While this is a real technical challenge today for enterprises, most challenges also represent product opportunities (e.g., new products that help enterprises deal with privacy risks).
- Model governance: Complex models, whether for generative AI or predictive ML use cases, are difficult to explain and track. This is challenging for regulators and for meeting audit needs, especially in highly regulated industries with significant impact on consumers, such as healthcare and financial services.
- Model security: Protecting data sets and the resulting model from tainted data, service attacks, or unauthorized users is key for enterprises facing potential adversarial threats on their generative AI models. We may also start to see LLM-powered cyber-attacks (e.g. like ransomware, but “smarter”).
Current LLMOps landscape
Click to expand the image below.

Vector databases, prompt engineering, model monitoring
We have seen a proliferation of tools in these three categories. Many of these companies have been launched in the last 12 months, while others, such as our portfolio companies, Weights & Biases, Fiddler, etc., have leveraged their existing MLops expertise and product capabilities to offer new features focused on LLMops.
Our portfolio company SingleStore recently launched a powerful vector database capability, similar to the LLM-focused single-purpose vector databases — but with the advantage of mature database features like autoscaling, high availability, ingest, lots of formats, etc., and it’s multi-modal so you can also use it for lots of other kinds of database workloads, and it likely already has your data in it (so less need for moving data around).
Compute optimization
As enterprises look to adopt generative AI, the efficiency of the inference infrastructure is proving to be a much more important and durable competitive differentiator than we expected, and advantages in efficiency seem to compound with scale. Being able to run the system at 90% lower cost and with fewer GPUs not only makes products higher gross margin but also can make the product qualitatively different and better. Some LLMOps products like Run:AI and Deci AI can help companies address different parts of this challenge.
Areas warranting more focus
We believe some critical pieces of the LLMops pipeline are currently underrepresented in the marketplace. Enterprises that hope to deploy full generative AI products are often “on their own” when it comes to some aspects of privacy, model security, and model governance (more information on generative AI governance can be found in our article here). Trust will likely be an important moat here, in that it is hard to build and can be quick to lose, making it an important source of competitive advantage.
What’s next?
One obvious shift we’ve noticed between the traditional “systems of prediction” AI and the newer “systems of creation” generative AI is how much easier it is for companies to implement useful generative AI capabilities in production. The years of work, employing teams of expensive machine learning engineers, constructing intricate data pipelines and machine learning infrastructures, and amassing extensive training, inference, and feedback data just don’t seem to be as important with generative AI as they were for prediction systems — at least so far.
Existing players can leverage their distribution, product capabilities, data, and customer trust to launch powerful LLM features to compete with generative AI startups before the startups can get to scale. This has yielded an early advantage for existing players (including fast-growing scaleups like those in the Insight portfolio) who are enjoying advantages over generative AI-native startups in the space, at least so far. Then again, it’s only been a few months.
Note: Jasper, Run:AI, Deci AI, Weights and Biases, Fiddler, SingleStore, Overjet, Iterative Health, ScreenPoint Medical, Tractable are all Insight portfolio companies.
This market map is up to date as of October 2023.








